
FAN3111C Overview
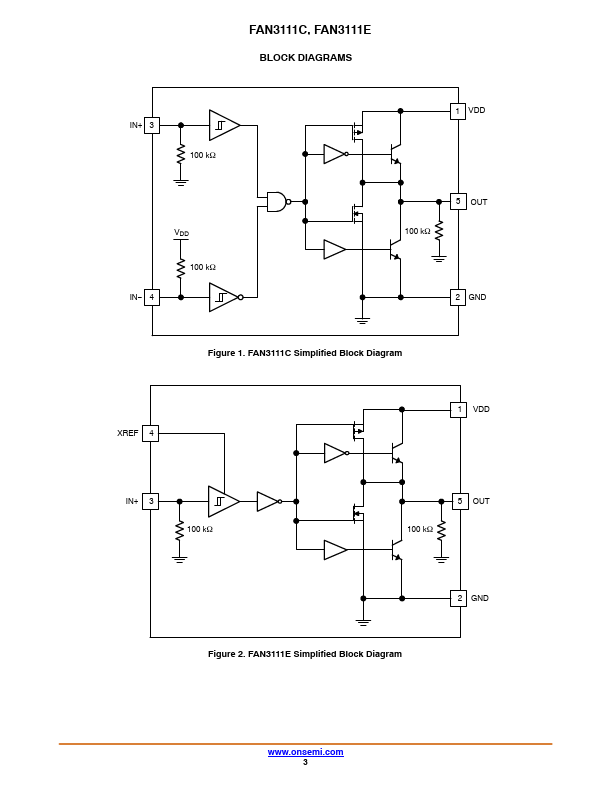
The FAN3111 1 A gate driver is designed to drive an N−channel enhancement−mode MOSFET in low−side switching applications. Two input options are offered: FAN3111C has dual CMOS inputs with thresholds referenced to VDD for use with PWM controllers and other input−signal sources that operate from the same supply voltage as the driver.
FAN3111C Key Features
- 1.4 A Peak Sink/Source at VDD = 12 V
- 1.1 A Sink/0.9 A Source at VOUT = 6 V
- 4.5 to 18 V Operating Range
- FAN3111C patible with FAN3100C Footprint
- Two Input Configurations
- Dual CMOS Inputs Allow Configuration as Non-Inverting or Inverting with Enable Function
- Single Non-Inverting, Low-Voltage Input for patibility with Low-Voltage Controllers
- 15 ns Typical Delay Times
- 9 ns Typical Rise/8 ns Typical Fall times with 470 pF Load
- 5-Pin SOT23 Package